The process of creating a base data set using a custom report involves going to the tenant’s data catalogue and selecting the appropriate custom report option, there are three options for creating a base data set: from a workday custom report, from a file or server, or from an SFTP.
The first workday Report is for importing the workday company structure, which does not have any selection criteria, the second workday report is for defining environment restrictions.
When a data set is created, it runs in an environment, which is a workday security proxy or proxy access policy, a data set is imported, it checks if the environment in which the base data set is being executed matches the restricted environment.
If there is a match, the workday integration will run and get the data, if there is no match, the data set will fail, this is an additional safety measure to prevent someone from accidentally importing production data into non-production systems.
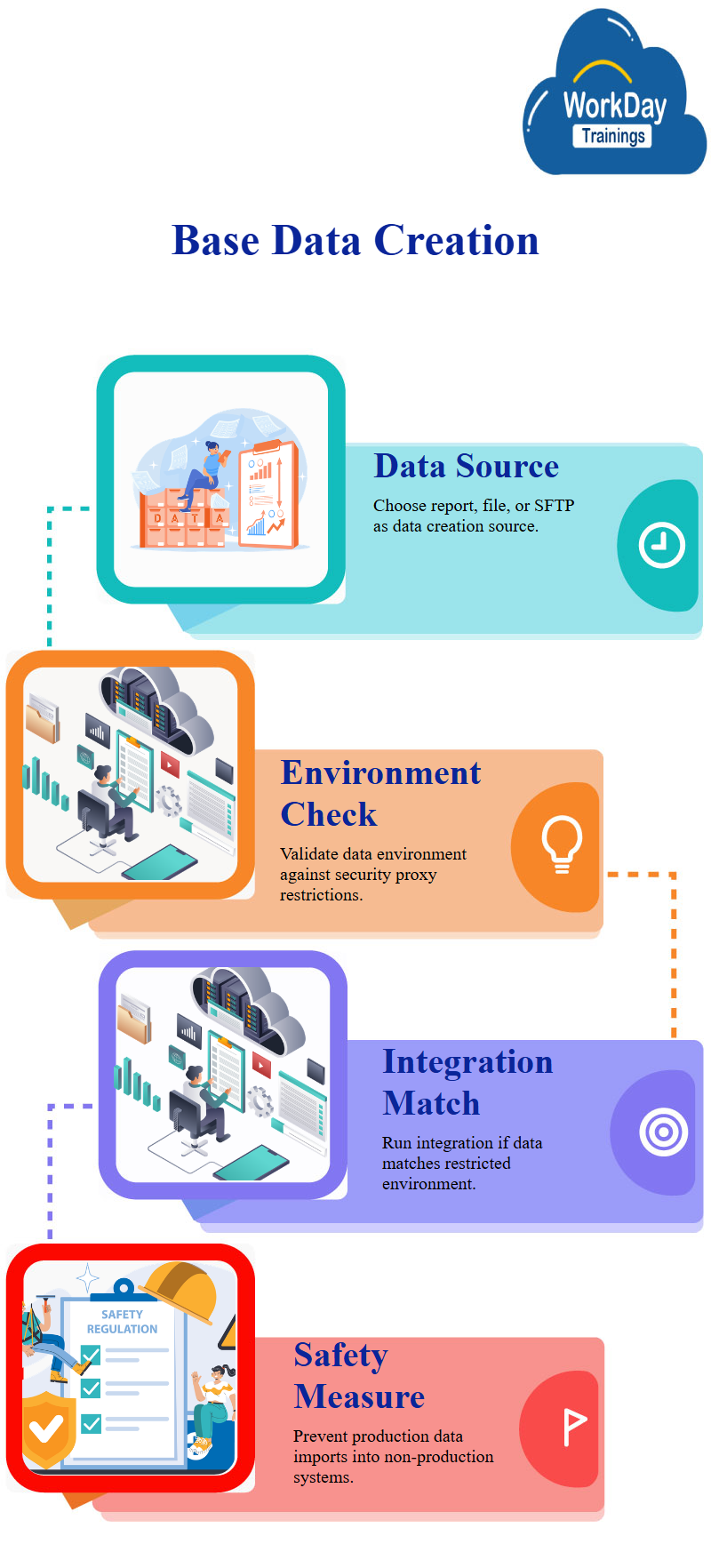
When running a data set to import data, it will compare the execution workday tenant and whether it is listed in the environment restrictions section, if there is a match, the data set will run in the specified environment or workday tenant.
If the environment restriction is not specified as production, the data set will fail, to create a data set, define the prompt values and select the environment in which you want to use the data set to import data.
The best practice is to not specify production as the environment before going live in sandbox and only specify production as the environment after it has gone live in production, the integration run schedule can be defined, either running now or scheduled for the future.
For now, the data set can be run now or on a daily or weekly basis, the custom report will fetch data based on the latest data available in workday and retrieve it into the data set.

Creating and Renaming Data Sets in Workday
The process of creating a data set in Workday, which can be renamed after saving, it emphasizes the importance of meaningful names and the fact that changing the name of the data set after saving is necessary.
The base data set, BDS, is created through a custom report or CR and imports the company structure or workday company details, the naming convention for DDS is derived from the data set.
Creating Data Sets with Tags and Filters in Workday
User creates a data set using a custom report or Workday report, which has not been modified since the last modification, they define tags for the data set and can either select an existing tag or create a new tag.
Workday automatically adds a primary pipeline with the same name as the data set and a stage called parse stage, users then filter on their tag and creates new base data sets for other workday custom reports.

Derived Data Sets in Workday: Importing Data from Multiple Sources and Creating Blended Reports
The base data set is the starting point for creating reports and allows for the importation of data into Workday, it consists of three types of source data: workday custom reports, SFTP, and Excel files.
These base data sets are created to import data from three separate sources: workday company structure, supervisory structure, and worker details, to bring this data together, a derived data set is created, which is based on one or more existing tables or data sets.
A derived data set is created using one or more existing tables or data sets, such as base data sets or other derived data sets, the source data of a derived data set comes from the output of existing tables or data sets.
When creating a base data set, Workday automatically adds a default stage into the pipeline, which is the part stage, data enters the base data set, goes through transformation in different stages, and finally comes out of the base data set.
The purpose of creating a derived data set is to blend data from different sources, both workday and non-workday, this process involves importing data from workday, non-workday, and multiple sources.
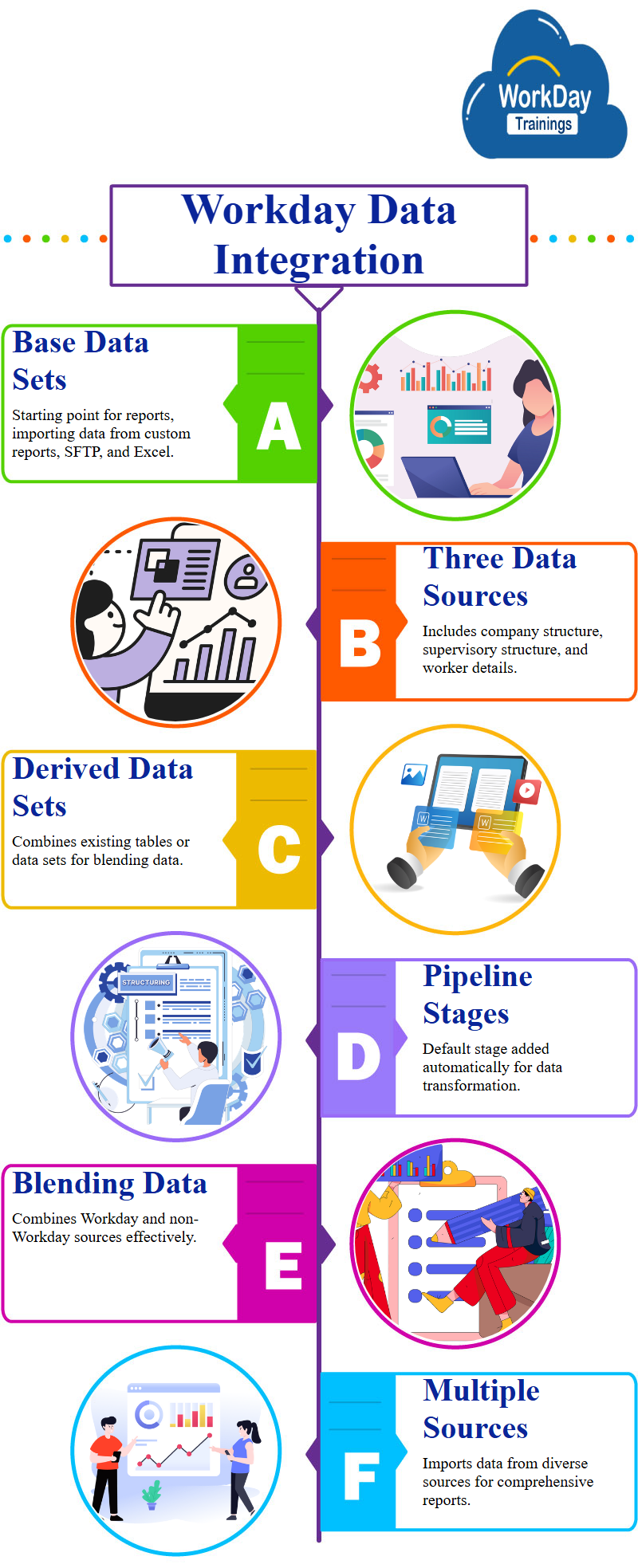
To create a derived data set, users can click on the “Create and Derived Data Set” button and specify the desired BDS.
When creating a derived data set, Workday automatically adds the primary pipeline for the first base data set, the primary pipeline is the primary source of data and can get data from multiple sources.
When creating a derived data set, Workday automatically adds the primary pipeline, which is import, the first stage of the primary pipeline is import, which is the first stage in the data catalogue.
In a base data set, the first stage is basically, and the base data set is imported by the derived data set, the system adds a stage within the primary pipeline, the power stage, and the primary pipeline within the import stage.
There is no change pipeline option in a derived data set, as there is only one pipeline, however, users can add a new pipeline if desired.
The output of the primary pipeline is the input of the data set, and when viewing the lineage, a downstream trend is created, while the upstream dependency is the data set being imported into the data set, this creates a two-way dependency between the two data sets.

Data Set Workspace: Managing and Viewing Data Sets
To access a data set, users can use the data set workspace, which is similar to the data catalogue workspace, allows users to view and edit data sets, view the lineage, and edit data sets, the workspace also displays all rows of data, fields, and columns, as well as Workday Prism analytics jobs about them.
Excel Data Set Workspace: Pipelines, Stages, and Field Selection
The data set workspace in Excel allows users to view a maximum of 20k rows of data, with the processing logic encapsulated in pipelines and stages, the pipeline details panel displays the pipeline list, which includes the primary pipeline, additional pipelines, and the ability to add any additional pipeline.
The pipeline details panel shows a list of all pipelines within the data set, as well as the stages they are part of, the data set workspace also displays a sample data section, which can be selected for further analysis.
If there are more than 20k rows, the data set can be resized to fit the desired size, for each stage, the stage statistics and relevant data are displayed, for example, the stage number eight has nine fields, while the stage number two has six fields and no workday calculated fields.

Creating a Data Set in Python with Calculated Fields
The process of creating a data set in Python, focusing on 11 fields, two of which are calculated fields, the inspector panel is displayed when a field is clicked on, showing two sections: field details and the functions library.
For workday calculated fields, the inspector panel shows all available functions, which can be selected by clicking on a plus icon or searching for them, the details section provides a brief workday description of the function, syntax, and data type returned.
Data Set Workspace and Inspector Panel
The data set workspace is accessed by clicking on edit and showing the pipeline list, pipeline details, and example data tables, the inspector panel consists of two sections: field info and the functions library.
The functions library is only shown for calculated means, such as field type, statistics, and top n values.

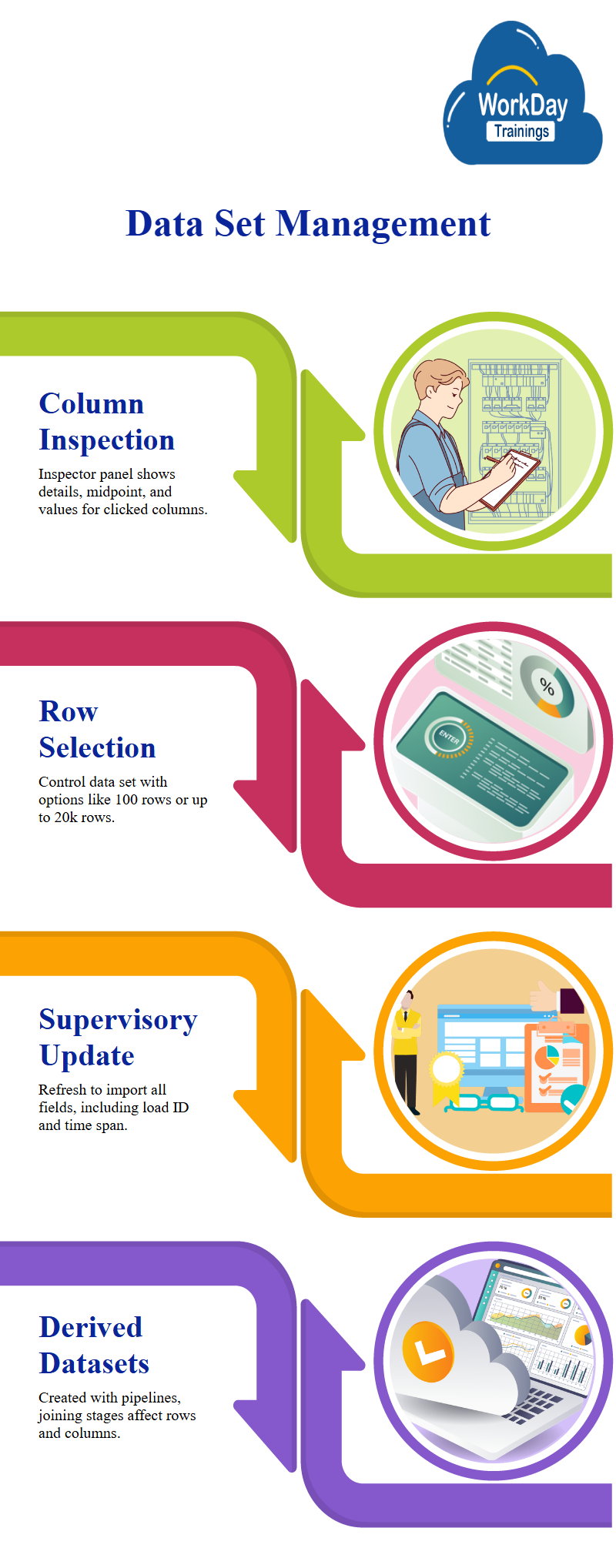
Column Detail Inspection with Customizable Data Set
When users click on a column, the inspector panel displays the details of that column, including the midpoint and values, the midpoint is based on the data in the column, and the data set can be controlled by selecting either 100 rows or 100 columns, 1k rows, or a maximum of 20k rows.
Updating the Supervisory Details Data Set
The base data set is named Supervisory details and is run in replace mode, users refresh the data set to import all fields and adds the load ID and load time span, the load ID for the new data set is different from the previous one, and the timestamp is different.
Creating Derived Datasets for Supervisory Organization Mapping
The creation of a derived data set, which includes two pipelines and a final output, the stage of joining the data sets may change the number of columns and rows, depending on the type of stage and available data.
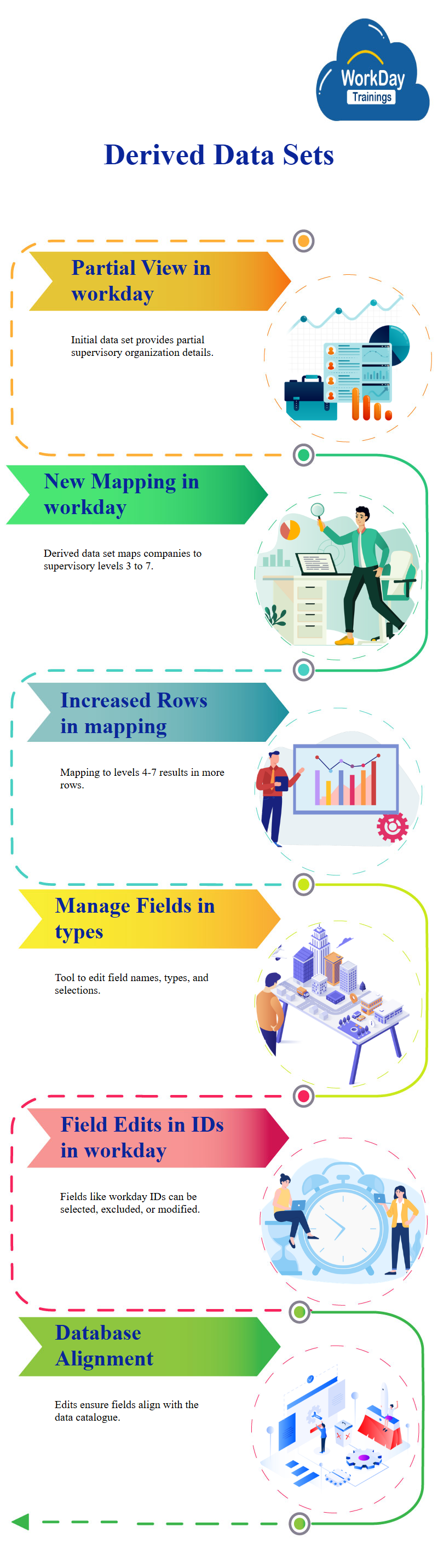
This derived data set that joins company details with supervisory details, but only provides a partial view of supervisory organizations, to identify other supervisory organizations, they create another derived data set.
Creates a new derived data set, DDS 0, 2, which maps companies to supervisory organizations up to level 3, they then map this data to subordinate supervisory organizations at levels 4 and 5, 6, and 7, this results in more rows than the original data set.
Managing Data with the Manage Field Stage
The manage field stage is a workday tool that allows users to change field types or names, select fields, edit fields, and view changes, it is essential for managing data in a database, as it allows users to select and edit fields, as well as view changes.
One of the main functions of the manage field stage is to edit field types, select fields, and view changes, users can edit field types, name, and select fields to ensure they are aligned with the data catalogue.
Another function of the manage field stage is to select and edit fields, users can edit fields like workday ID, load ID, and parent company workday ID, which are no longer needed for referencing or joins, users can also select which fields to include or exclude from subsequent stages.
The manage field stage also allows users to select which fields to include or exclude from subsequent stages, for example, users can edit workday IDs and load IDs for the second and third BDS.
Customizing Data Sets with BDS
The purpose of the BDS is to view field changes in data sets, initially, data was loaded through workday custom reports or external files, but over time, the system would continue to use these data sets.
To change the data source, users can edit the workday custom report add new fields, such as employee ID and age, this changes the data source, causing new fields to be added when importing data into the base data set.
Field Changes in Data Sources
Workday’s management stage allows users to view field changes in their data source, ensuring that subsequent systems are not affected, this is particularly important when dealing with third-party systems or data sources.
This handles schema changes based on the source file header, which includes XML aliases like worker name, employee ID, and worker types.
Workday uses the header rows to determine which fields have changed in the source file, allowing users to add or delete fields from any location in the source file.
However, if the source file does not have a header row, Workday only handles changes occurring at the end of the source file, therefore, it is recommended to include header rows in data sets when creating workday custom reports data sets.
Workday’s Management Stage Recommendation for Data Source
By adding a management stage as the first stage in your data source, as changes in the data source or fields won’t impact the BDS, this ensures that changes occur before publishing a data set, allowing for quick verification of all changes.
Organization Subtypes and Hierarchy in Workday
In Workday, organizations have subtypes that are associated with them, which are then used to join data, however, when creating a workday supervisory organization, the system creates a hierarchy of these workday organizations, for example, Global Modern Services has workday subtypes for information and technology, sales and marketing, and energy.
To handle the data, the system creates two types of sector fields: one is sector and the other is sector underscore view.
When creating a supervisory organization, it creates a subtype for each organization, such as global workday talent, human resources, and information technology, the subtypes are then extracted from the workday organization’s workday subtypes.
Life Sciences Subtype Division for Business Unit Extraction in Risk Management
For risk and management, the subtype is division, and the subtype underscore is Life Sciences, this allows for the extraction of the business unit for these organizations.
For instance, Risk Management has a subtype for division, but it is part of workday finance and administration, which is part of Life Sciences.
Customizing Prompt Values in a Supervisory Structure Report
Users creates a new base data set from a supervisory structure report and defines prompt values, the report has a prompt criterion, and the user must define the values for those criteria, users can specify the restricted environments and run frequency.

SFTP Data Set Creation Options
The three options for creating a base data set using SFTP are FTP, SFTP file, and workday custom report, SFTP files are similar to FTP files but are placed on a secure location.
Integrations can consume multiple files at the same time, with file name patterns defining placeholders like question marks or asterisks, allows for up to a maximum of thousand files to be consumed.
Scheduling Data Sets in Workday
Workday offers various options for scheduling data sets, such as daily, weekly, or monthly, these schedules can be defined based on start time, time zone, catch-up behavior, start date, and end date, and prioritized by workday.
The system prioritizes tasks with high workloads, ensuring that everything runs through workday.
Data-Dependent Scheduling for Data Acquisition and Publication
A dependent schedule can also be created, which depends on new data coming in, this schedule can be dependent on the data acquisition process, which is where the data set data is acquired.
If the data acquisition process is not scheduled, publishing will only happen after the successful completion of the data acquisition schedule.

Harsha
New Technology, let's explore together!

