Files workday vs workday Integrations for Dynamic Data Management
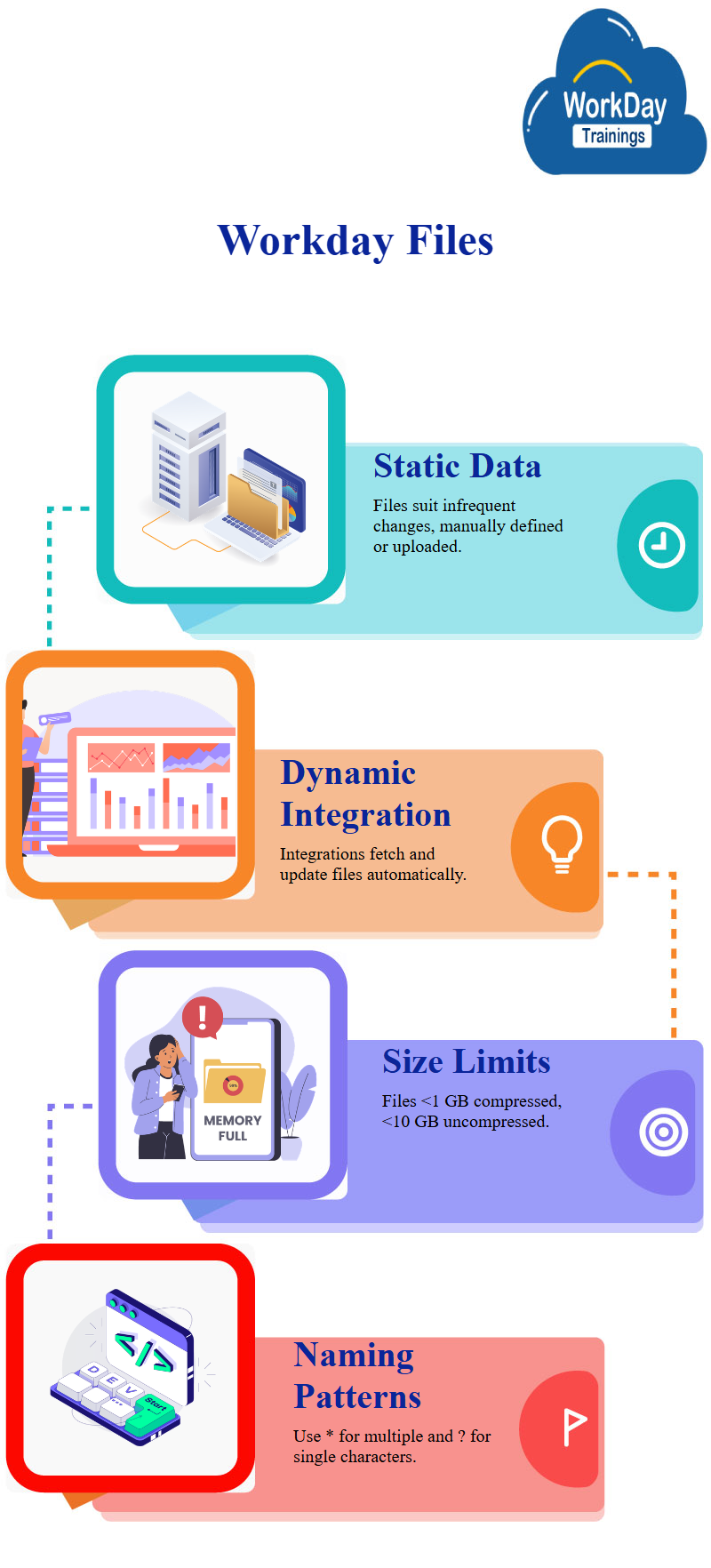
Files are suitable for data that doesn’t change frequently, as they can be manually defined or uploaded, however, once defined, integrations can automatically run and fetch the files and any new ones. This option is usually used when the source data changes often.
File size and transfer limitations for Data Integration
Limited recommendations include a number of files less than thousand, a time to transfer data in a single workday integration run of less than six hours, and each file must be less than one GB compressed or 10 GB uncompressed.
File names or pattern patterns can be specified in star format, which specifies zero or more characters, and question mark format, specifying exactly one character.
Importing Data in Workday: Temp File Recommendation for Large Loads
When data is imported into Prism Workday, it is first imported into a temporary file after the data load has finished, this is recommended for large amounts of data and helps prevent data failures. If the data load is complete, the system automatically deletes the temporary file.
File Integration and Removal Options
If the source file is not deleted, the integration will fail, it removes confusion and allows new files to be placed, however, if the file deletion fails, the entire integration may fail.
Delete File on SFTP Server after Import
It is “delete after the tree will,” which deletes the file on the SFTP server after the data is imported into the data set, however, this is not recommended as it can directly use uncompressed data.
Integration Scheduling Management
To schedule an integration, users can define the integration: run, run now, or schedule that integration, the data retrieval integration schedule can also be defined.
For example, if the base data set has worker details and Prisma workday company details, the integration can automatically import data whenever there is a new or daily change.
To schedule the integration, users can either run it now or edit the integration details, the initial transport protocol can be defined, and the run frequency can be set to run on a daily or weekly basis, the start time, time zone, and catch-up behavior can be defined.
The integration in the system should be configured to run at a specific frequency, such as three times or once, depending on the data source.
Role of Truncate in Data Sets
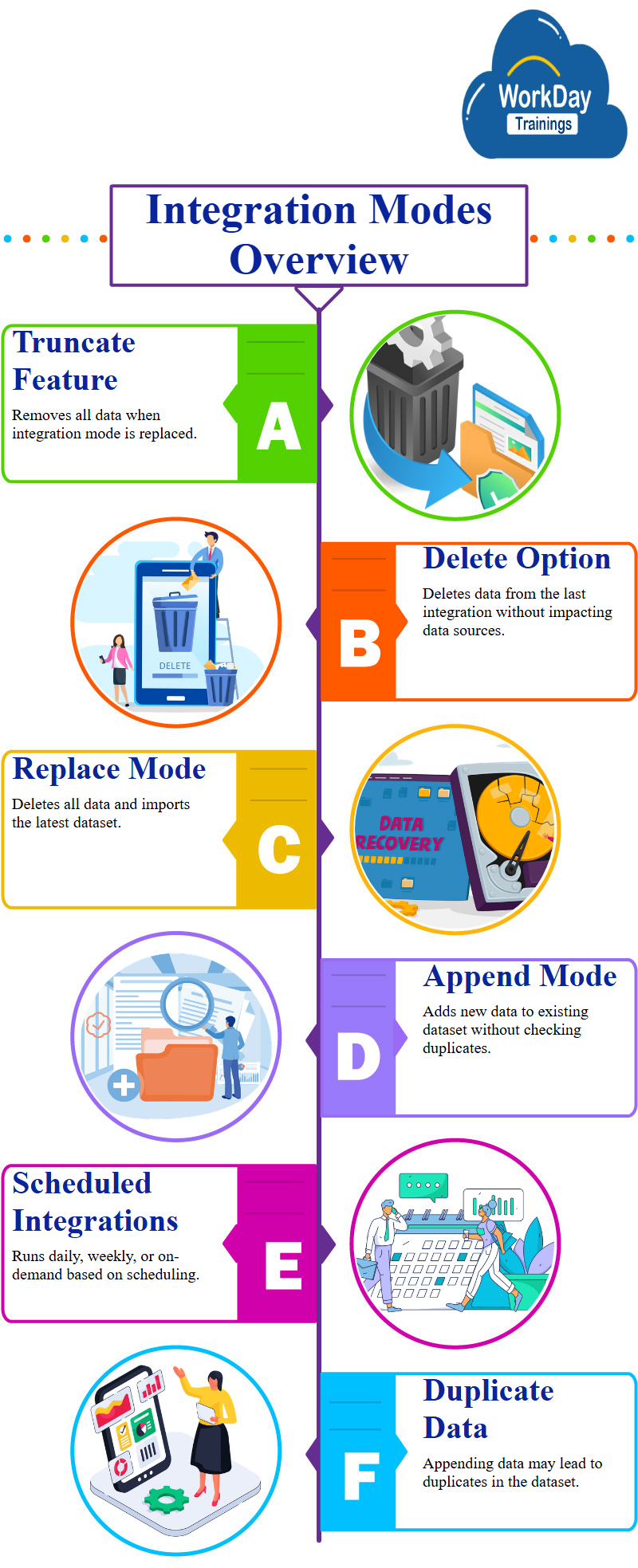
Truncate is a feature that removes all data from the data set, especially when the integration mode is replaced, it is only relevant when the integration mode is append.
If you want to delete data from the last integration run, you can use the delete option, however, if you delete any field from the derived data set, it will not impact your data source.
Append workday vs workday
When running an integration, the data set is scheduled to run on a recurring, daily, weekly, or even later basis, when importing new data, it is either replaced or appended.
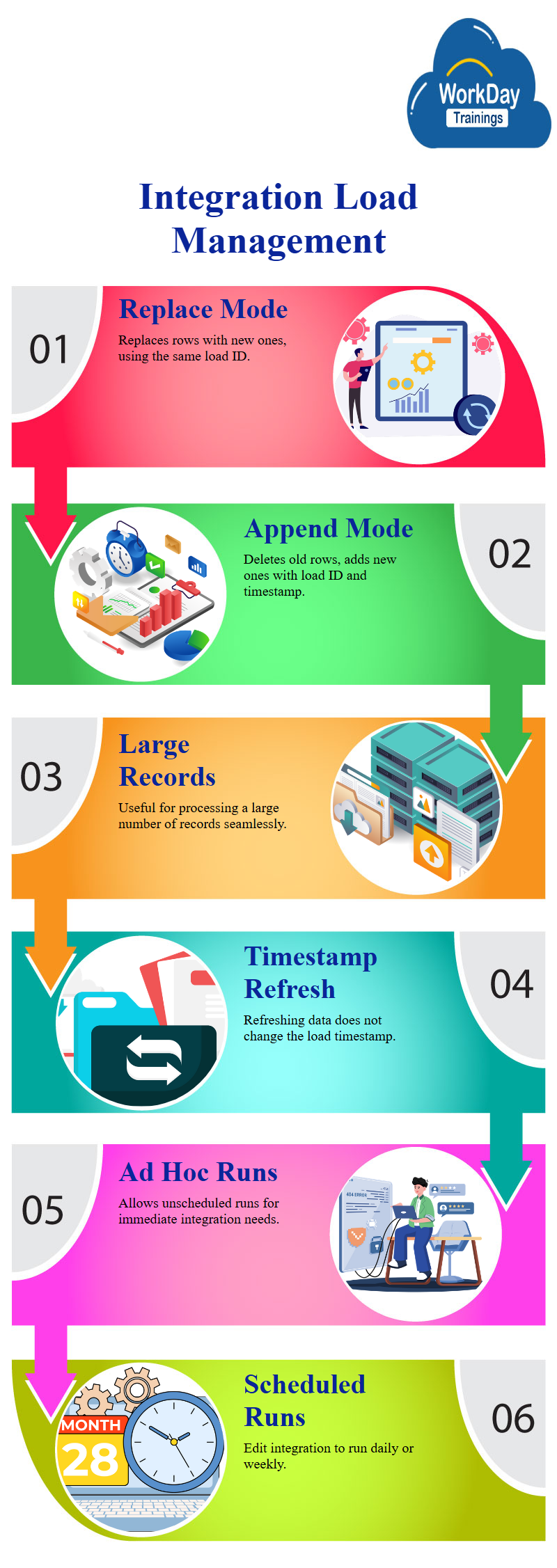
In replace mode, all existing data is deleted and replaced with the new data imported from the custom report during each integration run, this results in a blank data set and the latest data being added.
In append mode, the existing data remains as is and the new data is added, however, this mode may not check for duplicates as the system simply adds the new data from the custom report to the existing data, this can result in duplicate data in the data set.
Append mode is used when maintaining a snapshot of the custom report data set for trending use cases, this mode is only used when the data set needs to maintain a history of how the data is changing over time.
By default, replace mode is used only when specific environment requirements require maintaining old history, if you do not need to use append mode, you should select replace mode.
Workday Table View with Additional Fields for Append Mode
The table view shows all data from the custom report, including company name, WID, sector, parent company, and WID, also adds two additional fields: WPA load ID and WPA load timestamp.
These fields are useful in append mode, where data is continuously added, the load ID is the unique identifier of the integration run that imported the current row of data into the data set, and the timestamp is the date and time of the integration run that imported the data.
Load ID Management in Data Integration.
In replace mode, every row with the same load ID is the same, as everything gets replaced and new rows are added. In append mode, all existing rows are deleted and new rows are added, with the same load ID and timestamp. Refreshing the data set does not change the time, but it is only used when the integration is running. This is especially useful when loading a large number of records.
Ad Hoc Integration Running
When rerunning an integration, the load timestamp will automatically change, users can edit the integration details and schedule it to run on a daily or weekly basis, for now, they want to run the workday integration on an ad hoc basis.