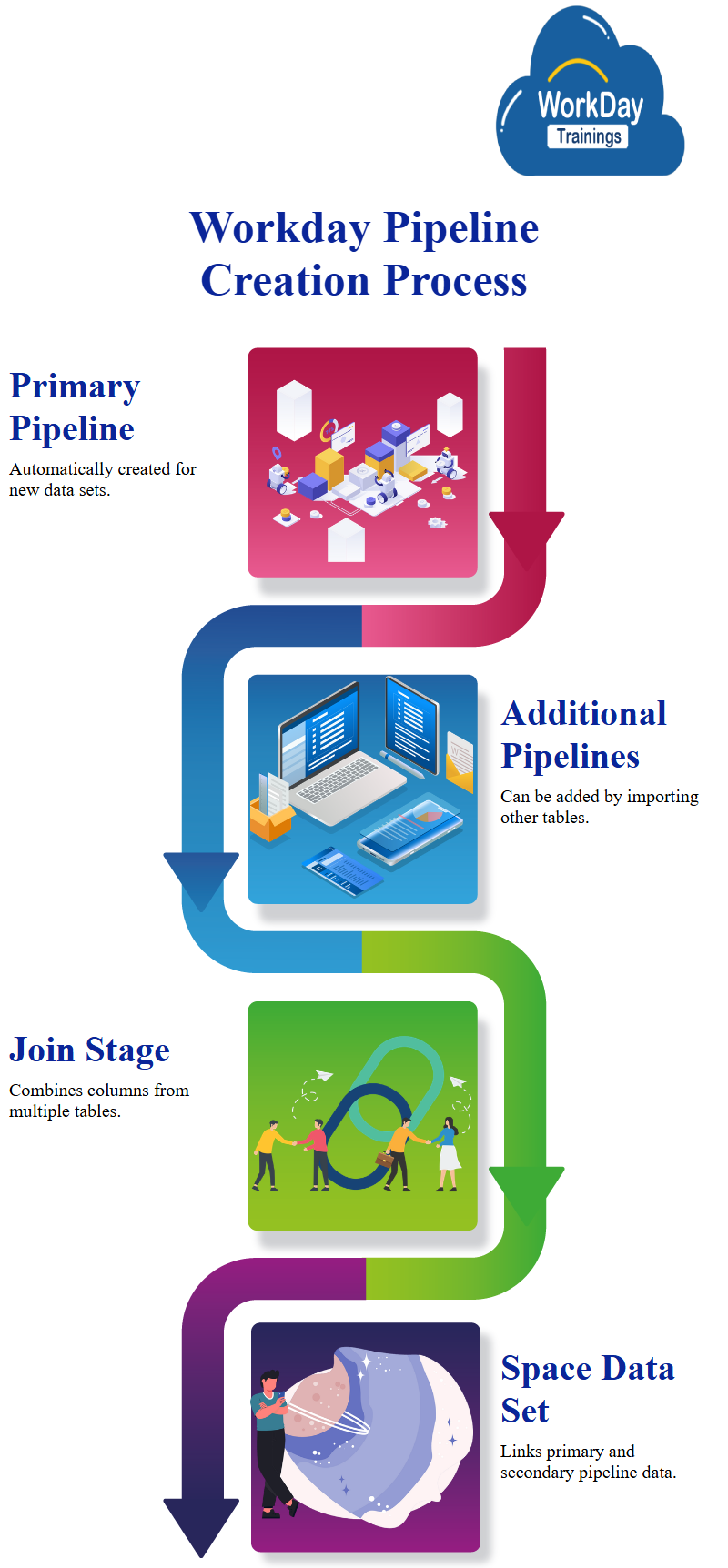
Workday automatically creates a primary pipeline when a data set is created, and any number of additional pipelines can be added by importing other tables and data sets, however, some pipelines can only be added to derived data sets.
Adding Join Stages for Multiple Table Cells
To create a single table with cells from multiple tables or columns from multiple tables, a join stage is added, this allows you to join columns from multiple tables.
When you select join, the system asks you for the secondary pipeline, instead of adding a secondary pipeline manually, you can add a join stage on your primary pipeline.
When you select join, the system will ask you what another pipeline you want to join with your primary pipeline.
Select the space data set and select it, this joins data from your primary pipeline with data from your secondary pipeline, creating a secondary pipeline for you.
Database Query Manual
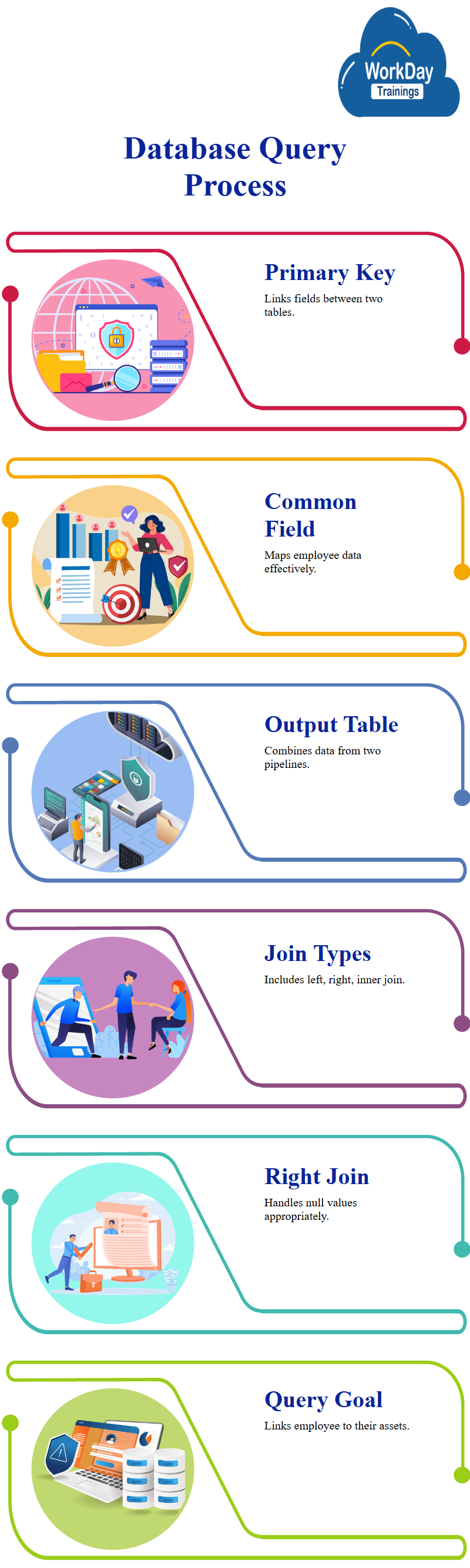
A query to join two tables, identifying which employee has which asset in the primary pipeline and which column is a match, the primary key used is ID, which is used to link the two tables.
The primary key is used to identify which field in the primary pipeline links to which field in the secondary pipeline, the primary pipeline contains company name, company ID, sector, parent company, parent company ID, WPA load ID, and stamp.
The common field is sector, which is used to map the employee ID to the employee’s name, date of birth, set ID, and set back, the output table is the final table with all data from the left pipeline and all data from the right pipeline.
The type of joint determines the output table, if there is no map, the data is found, other types of joints include left right and inner join.
The right type will give only even a two and admin, while the right type will give null values. The query aims to identify which employee has which asset in the primary and secondary pipelines.
Data Transformation Techniques in Data Preparation
Data preparation involves preparing data by creating derived data sets, which are two different data sets: base data sets and derived data sets, data is transformed through pipelines and stages, which allow joining, union, prism calculations, and managing fields, data is transformed by joining, blending, adding modifications, and calculations.
Automatic Pipeline and Stage Addition with Workday
Workday automatically adds a primary pipeline and a stage called parse stage, users save the new tag and returns to their data catalogue, showing two base data sets.
Single Primary Pipeline in Base Data Set
A base data set contains only one primary pipeline, which cannot be added to, this means that when you create a derived data set, Workday Prism cost automatically adds the primary pipeline, ensuring that any data set will always have one pipeline.
However, a derived data set can have multiple pipelines, with the output of each pipeline being the output of the primary pipeline.